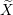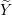Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Current β λ ∈ ℝ Grid element 1:ϵ ← Xβ − Y 2:fβ←||ϵ||22 + λ||β||1 Primal Objective function 3:α ← 4:α0← YTϵ 5:← min{max{α,α0},−α} Dual Point 6:←ϵ + Y 7:dν←λ2||||22−||Y ||22 Dual Objective function
return fβ + dν
Algorithm 2: DGT ( Duality Gap Target )
Input: γ ∈ ℝ … C ∈ ℝ … rStatsIt∈ ℕ Index of the current grid element ( outer loop iteration number ) n ∈ ℕ Number of rows in the design matrix X ∈ ℝn×p 1:dgt ← γC2
return dgt
Algorithm 3: fβ
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Current β 1:f ← Xβ − Y .
return ||f||22
Algorithm 4: f
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn The k’th β vector β′∈ ℝn The k − 1’th β vector L ∈ ℝ The current Lipschitz constant, as computed by backtracking line search 1:f ← Xβ − Y . 2:t0←||f||22 3:∇f ← 2XTf 4:Δβ← β − β′ 5:t1←∇fTΔβ 6:t2←||Δβ||22
Input: X ∈ ℝn×m An arbitrary matrix λ ∈ ℝ The thresholding parameter 1:← X Make a copy of X. 2:fori,j∈do 3:i,j← sign(i,j)+ 4:endfor
return
Algorithm 6: ISTA with backtracking line search and duality gap convergence criteria
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector L0∈ ℝ Initial Lipschitz constant, used by backtracking line search λ ∈ ℝ Grid element η ∈ ℝ Step size when updating Lipschitz constant ∈ ℝ Duality gap target 1:← β Make a copy of β that will be updated during back tracking. 2:do 3:← τ(β −∇f(X,Y,,L)) 4:whilefβ(X,Y, ) > f(X,Y,,β,L) do 5:L ← ηL 6:← τ(β −∇f(X,Y,β)) 7:endwhile 8:β ← τ(β −∇f(X,Y,β,L)) Update β once L is sufficiently large. 9:while DG (X,Y,β,λ) > 10:
return β
Algorithm 7: Coordinate Descent with duality gap convergence criteria
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector λ ∈ ℝ Grid element ∈ ℝ Duality gap target 1:← β Make a copy of β 2:do 3:fori ∈ 1,2,…,p do 4:t ← Scale grid element by norm of the i’th column of design matrix 5:X−i← X∀j≠i Take all columns of design matrix not equal to i 6:−i←∀j≠i Take all elements of predictors vectors not equal to i 7:r ← Compute the scaled residual 8:i← τ Update the i’th element of Beta 9:endfor 10:while DG (X,Y,,λ) > 11:
return
Algorithm 8: Coordinate Descent with Lazy Evaluation
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector λ ∈ ℝ Grid element ∈ ℝ Duality gap target 1:← β Make a copy of β 2:R ← Y − X Initialize Intermediary Residual 3:do 4:fori ∈ 1,2,…,p do 5:t ← Scale grid element by norm of the i’th column of design matrix 6:ifi≠0 then R ← R + Xii 7:endif 8:i← τ Update the i’th element of Beta 9:ifi≠0 then R ← R − Xii 10:endif 11:endfor 12:while DG (X,Y,,λ) > 13:
return
Algorithm 9: Coordinate Descent with standardized data
Input: X ∈ ℝn×p The standardized Xi = 0,σXi = 1 design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector λ ∈ ℝ Grid element ∈ ℝ Duality gap target 1:← β Make a copy of β 2:do 3:fori ∈ 1,2,…,p do 4:t ← Scale grid element by norm of the i’th column of design matrix 5:X−i← X∀j≠i Take all columns of design matrix not equal to i 6:−i←∀j≠i Take all elements of predictors vectors not equal to i 7:r ← Compute the scaled residual 8:i← τ Update the i’th element of Beta 9:endfor 10:while DG (X,Y,,λ) > 11:
return
The next algorthim is a modified version of Coordinate Descent that seeks to reduce redunant
computations as much as possible. This algorthim relies on the fact that many computation required by
Coordinate Descent can be broken up into constant and non-constant parts. The constant parts of the
computation can be performed ahead of time and stored for later use.
Of particular note is the scaled residual computation, which when written down naively
reads:
r ←.
Which we can re-write as,
r ←−−i.
Note that since the design matrix X and the vector of predictors Y are fixed, the terms and
do not change as the values of are updated. Our strategy will be to compute these values for
each column of X and store them in an array of size p, from which they will be access as is
updated.
Note for this algorthim we establish the convention that array of a given data type will be declared as
follows:
( type )[ # elements in array ]
As an example an array of real numbers numbers of size n ∈ ℕ would be written as:
( ℝ )[ n ]
Algorithm 10: Coordinate Descent with Minimal Data Copying
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector λ ∈ ℝ Grid element ∈ ℝ Duality gap target 1:ℷ ← (ℝ)[p] Initialize array of size p to hold threshold parameters 2:p1∈ (ℝ)[p] Blank array for part of residual computation 3:p2∈ (ℝ1×p)[p] Blank array to row vectors of size p which will be used for part of residual computation 4:fori ∈ 1,2,…,p do 5:ℶ ← 6:ℷ[i] ←ℶ 7:p1[i] ← ℶXiTY 8:p2[i] ← ℶXiTX 9:endfor 10:← β Make a copy of β 11:do 12:fori ∈ 1,2,…,p do 13:←jif j≠i else 0 Copy all of beta expect i’th element which is assigned to 0 14:r ← p1[i] − p2[i] Compute the scaled residual 15:t ← λℷ[i] Compute threshold parameter 16:i← τ Update the i’th element of Beta 17:endfor 18:while DG (X,Y,,λ) > 19:
return
Algorithm 11: FISTA with backtracking line search and duality gap convergence criteria
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector L0∈ ℝ Initial Lipschitz constant, used by backtracking line search λ ∈ ℝ Grid element η ∈ ℝ Step size when updating Lipschitz constant ∈ ℝ Duality gap target yk−1∈ ℝb Beta vector from previous iteration of FISTA xk−1∈ ℝb Intermediary vector from previous iteration of FISTA 1:yk← β 2:do 3:yk−1← xk 4:tk← 0 5:← τ(β −∇f(X,Y,yk)) 6:whilefβ(X,Y,) > f(X,Y,,yk,L) do 7:L ← ηL 8:← τ(β −∇f(X,Y,β)) 9:endwhile 10:xk−1← xk 11:xk← τ(β −∇f(X,Y,)) 12:tk+1 = 13:yk← xk + 14:while DG (X,Y,β,λ) > 15:
return yk,yk−1,xk−1,tk+1
Algorithm 12: λGRID
Input: X ∈ ℝn×m The design matrix Y ∈ ℝn The vector of predictors M ∈ ℕ The number of grid elements required 1:rmax← 2||XTY ||∞ 2:rmin←rmax 3:Δr← 4:Let Λ ∈ ℝM Initialize empty array of size M 5:fori ∈ [1,2,…,M] do 6:δl← Δr + rmin Compute linear step 7: Λ[i] ← 10δl Convert to logarithmic step 8:endfor
return Λ
Algorithm 13: SCC: Stats Continutation Condition
Input: C ∈ ℝ The design matrix statsIt ∈ ℕ The vector of predictors λ ∈ ℝ Current grid element Λ ∈ ℝM Vector of grid elements X ∈ ℝn×p Vector of grid elements βs∈ ℝn×M Betas matrix 1:condition ← false 2:fori ∈ [1,2,…,statsIt] do 3:rk← Λk 4: Δβ← βstatsIt− βi 5: check ← 6: condition ← condition & ( check ≤ C ) 7:endfor
return condition
Algorithm 14: FOS
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝn Starting vector L0∈ ℝ Initial Lipschitz constant, used by backtracking line search M ∈ M Number of grid elements η ∈ ℝ Step size when updating Lipschitz constant C ∈ ℝ γ ∈ ℝ 1:←. Normalize X to mean 0 and standard deviation 1. 2:←. Normalize Y. 3:Λ ← λGRID(X,Y,M) Initialize grid elements 4:βs∈ ℝn×m = 0n,m. Initialize matrix of Betas to zero matrix 5:while statsCont & ( statsCont < M ) do 6:statsIt← statsIt + 1 7:← βk−1 Initialize old beta vector with the k - 1’th Column of the Betas matrix. 8:rstatsIt← Λk Extract the k’th grid element. 9:ifDG(X,Y,βk,rstatsIt) ≤ DGT(γ,C,rstatsIt,n) then 10:βk← βk−1 11:else 12:βk← ISTA(X,Y,βk−1,L0,rstatsIt,η,gap) 13:endif 14:statsCont ← SCC (C,statsIt,rstatsIt,Λ,X,βs) 15:endwhile
return βstatsIt−1,ΛstatsIt,statsIt
Algorithm 15: DP ( Dual Point )
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝp Current β λ ∈ ℝ Grid element 1:R ← Y − Xβ 2:α ← 3:s ← min{max{,−α},α}
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝp Current primal point ν ∈ ℝn Current dual point λ ∈ ℝ Grid element 1:fβ←||Y − Xβ||22 + λ||β||1 Primal Objective function 2:dν←||Y ||22−||ν −||22 Dual Objective function
return fβ− dν
Algorithm 17: SAS ( Safe Active Set )
Input: X ∈ ℝn×p The design matrix c ∈ ℝn Center of the ball r ≥ 0 Radius of the ball 1:←∅ Initialize Active Set With Empty Set 2:forj ∈{1,…,p}do 3:if|XjTc| + r∥Xj∥2≥ 1 then 4:←∪{j} 5:endif 6:endfor
return
Algorithm 18: CDSR (Coordinate Descent With Lazy Evaluation and Screening Rule)
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors β ∈ ℝp Starting vector λ ∈ ℝ Grid element ∈ ℝ Duality gap target 1:← β Make a copy of β 2:R ← Y − X Initialize Intermediary Residual 3:←{1,…,p} Initialize Active Set 4:optimCont ← true 5:while optimCont do 6:ν ← DP(X,Y,,λ) Dual point 7:← DG2(X,Y,,ν,λ) Duality gap 8:← SAS(X,ν,) Safe Active Set 9:if≤then 10:optimCont ← false 11:else 12:fori ∈do 13:t ← Scale grid element by norm of the i’th column of design matrix 14:ifi≠0 then R ← R + Xii 15:endif 16:i← τ Update the i’th element of Beta 17:ifi≠0 then R ← R − Xii 18:endif 19:endfor 20:endif 21:c = 0 Set to 0 coefficients not in 22:endwhile
Input: X ∈ ℝn×p The design matrix Y ∈ ℝn The vector of predictors M ∈ ℕ Number of grid elements C > 0 γ > 0 1:← Normalize X to mean 0 and standard deviation 1. 2:← Normalize Y. 3:Λ ← λGRID(,,M) Initialize grid elements 4:βs∈ ℝp×M← 0p,M Initialize matrix of Betas to zero matrix 5:statsCont ← true 6:statsIt ← 1 7:while statsCont & ( statsIt < M ) do 8:statsIt ← statsIt + 1 9:← DGT(γ,C,ΛstatsIt,n) Duality gap target 10:βstatsIt← CDSR(,,βstatsIt−1,ΛstatsIt∕2,∕2) 11:statsCont ← SCC (C,statsIt,ΛstatsIt,Λ,X,βs) 12:endwhile
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Current
Current  Grid element
Grid element  Primal Objective function
Primal Objective function 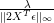
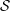 ←
← Dual Point
Dual Point 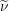
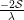
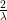
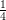
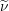
 Dual Objective function
Dual Objective function
 …
…  …
…  Index of the current grid element ( outer loop iteration number )
Index of the current grid element ( outer loop iteration number )  Number of rows in the design matrix
Number of rows in the design matrix 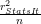
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Current
Current 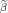
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  The
The  The
The  The current Lipschitz constant, as computed by backtracking line search
The current Lipschitz constant, as computed by backtracking line search 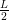
 An arbitrary matrix
An arbitrary matrix  The thresholding parameter
The thresholding parameter 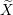
 Make a copy of
Make a copy of 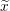
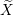
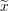
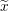
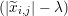
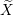
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Initial Lipschitz constant, used by backtracking line search
Initial Lipschitz constant, used by backtracking line search  Grid element
Grid element  Step size when updating Lipschitz constant
Step size when updating Lipschitz constant 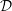 ∈
∈  Duality gap target
Duality gap target 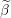
 Make a copy of
Make a copy of 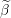
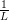
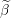
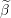 )
) 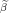 (
(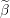
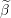
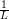
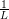
 Update
Update  The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Grid element
Grid element  Duality gap target
Duality gap target 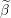
 Make a copy of
Make a copy of 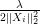
 Scale grid element by norm of the i’th column of design matrix
Scale grid element by norm of the i’th column of design matrix  Take all columns of design matrix not equal to
Take all columns of design matrix not equal to 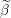
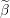
 Take all elements of predictors vectors not equal to
Take all elements of predictors vectors not equal to 
 Compute the scaled residual
Compute the scaled residual 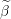
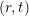
 Update the i’th element of Beta
Update the i’th element of Beta 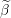
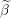
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Grid element
Grid element  Duality gap target
Duality gap target 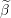
 Make a copy of
Make a copy of 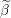
 Initialize Intermediary Residual
Initialize Intermediary Residual 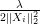
 Scale grid element by norm of the i’th column of design matrix
Scale grid element by norm of the i’th column of design matrix 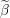
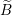
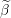
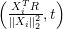
 Update the i’th element of Beta
Update the i’th element of Beta 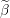
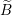
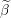
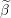
 The standardized
The standardized  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Grid element
Grid element  Duality gap target
Duality gap target 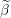
 Make a copy of
Make a copy of 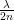
 Scale grid element by norm of the i’th column of design matrix
Scale grid element by norm of the i’th column of design matrix  Take all columns of design matrix not equal to
Take all columns of design matrix not equal to 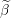
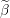
 Take all elements of predictors vectors not equal to
Take all elements of predictors vectors not equal to 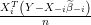
 Compute the scaled residual
Compute the scaled residual 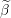
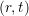
 Update the i’th element of Beta
Update the i’th element of Beta 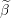
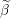
 .
.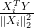
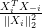
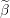
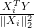 and
and
 do not change as the values of
do not change as the values of 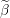 are updated. Our strategy will be to compute these values for
each column of
are updated. Our strategy will be to compute these values for
each column of 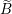 is
updated.
is
updated.
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Grid element
Grid element  Duality gap target
Duality gap target  Initialize array of size p to hold threshold parameters
Initialize array of size p to hold threshold parameters  Blank array for part of residual computation
Blank array for part of residual computation  Blank array to row vectors of size p which will be used for part of residual computation
Blank array to row vectors of size p which will be used for part of residual computation 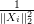
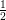
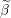
 Make a copy of
Make a copy of 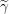
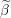
 Copy all of beta expect i’th element which is assigned to 0
Copy all of beta expect i’th element which is assigned to 0 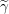
 Compute the scaled residual
Compute the scaled residual  Compute threshold parameter
Compute threshold parameter 
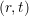
 Update the i’th element of Beta
Update the i’th element of Beta 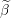
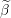
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Initial Lipschitz constant, used by backtracking line search
Initial Lipschitz constant, used by backtracking line search  Grid element
Grid element  Step size when updating Lipschitz constant
Step size when updating Lipschitz constant  Duality gap target
Duality gap target  Beta vector from previous iteration of FISTA
Beta vector from previous iteration of FISTA  Intermediary vector from previous iteration of FISTA
Intermediary vector from previous iteration of FISTA 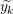
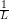
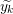 )
) 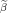 (
(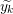
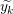
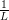
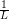
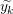 ))
)) 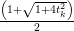
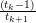
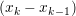
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  The number of grid elements required
The number of grid elements required 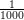
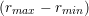
 Initialize empty array of size M
Initialize empty array of size M 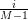 +
+  Compute linear step
Compute linear step  Convert to logarithmic step
Convert to logarithmic step  The design matrix
The design matrix  The vector of predictors
The vector of predictors  Current grid element
Current grid element  Vector of grid elements
Vector of grid elements  Vector of grid elements
Vector of grid elements  Betas matrix
Betas matrix 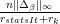
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Initial Lipschitz constant, used by backtracking line search
Initial Lipschitz constant, used by backtracking line search  Number of grid elements
Number of grid elements  Step size when updating Lipschitz constant
Step size when updating Lipschitz constant 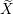
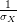
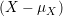 .
.  Normalize X to mean 0 and standard deviation 1.
Normalize X to mean 0 and standard deviation 1. 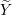
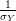
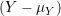 .
.  Normalize Y.
Normalize Y.  Initialize grid elements
Initialize grid elements  Initialize matrix of Betas to zero matrix
Initialize matrix of Betas to zero matrix 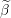
 Initialize old beta vector with the k - 1’th Column of the Betas matrix.
Initialize old beta vector with the k - 1’th Column of the Betas matrix.  Extract the k’th grid element.
Extract the k’th grid element.  The design matrix
The design matrix  The vector of predictors
The vector of predictors  Current
Current  Grid element
Grid element 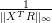
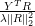
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Current primal point
Current primal point  Current dual point
Current dual point  Grid element
Grid element 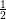
 Primal Objective function
Primal Objective function 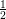
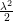
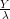
 Dual Objective function
Dual Objective function The design matrix
The design matrix  Center of the ball
Center of the ball  Radius of the ball
Radius of the ball 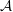 ←∅
←∅ Initialize Active Set With Empty Set
Initialize Active Set With Empty Set  The design matrix
The design matrix  The vector of predictors
The vector of predictors  Starting vector
Starting vector  Grid element
Grid element  Duality gap target
Duality gap target 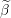
 Make a copy of
Make a copy of 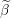
 Initialize Intermediary Residual
Initialize Intermediary Residual  Initialize Active Set
Initialize Active Set 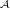
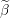
 Dual point
Dual point 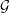 ←
←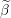
 Duality gap
Duality gap 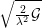 )
)  Safe Active Set
Safe Active Set 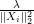
 Scale grid element by norm of the i’th column of design matrix
Scale grid element by norm of the i’th column of design matrix 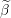
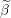
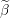
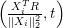
 Update the i’th element of Beta
Update the i’th element of Beta 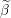
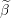
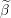
 Set to 0 coefficients not in
Set to 0 coefficients not in 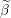
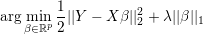
 The design matrix
The design matrix  The vector of predictors
The vector of predictors  Number of grid elements
Number of grid elements 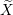
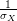
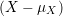
 Normalize X to mean 0 and standard deviation 1.
Normalize X to mean 0 and standard deviation 1. 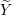
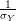
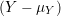
 Normalize Y.
Normalize Y. 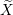
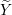
 Initialize grid elements
Initialize grid elements  Initialize matrix of Betas to zero matrix
Initialize matrix of Betas to zero matrix  Duality gap target
Duality gap target